Audacity получил набор бесплатных ИИ-плагинов для редактирования аудиосигнала и генерации музыки — SAMESOUND
Плагины Music Generation и Music Style работают на основе модели Stable Diffusion и её ответвления Riffusion . Инструменты генерируют музыку прямо в программе, полагаясь на текстовый запрос пользователя или одну из аудиодорожек в проекте. Music Generation призван придумывать фоновые дорожки с музыкой, в то время как Music Style предназначен для смены стилистики уже существующих композиций.
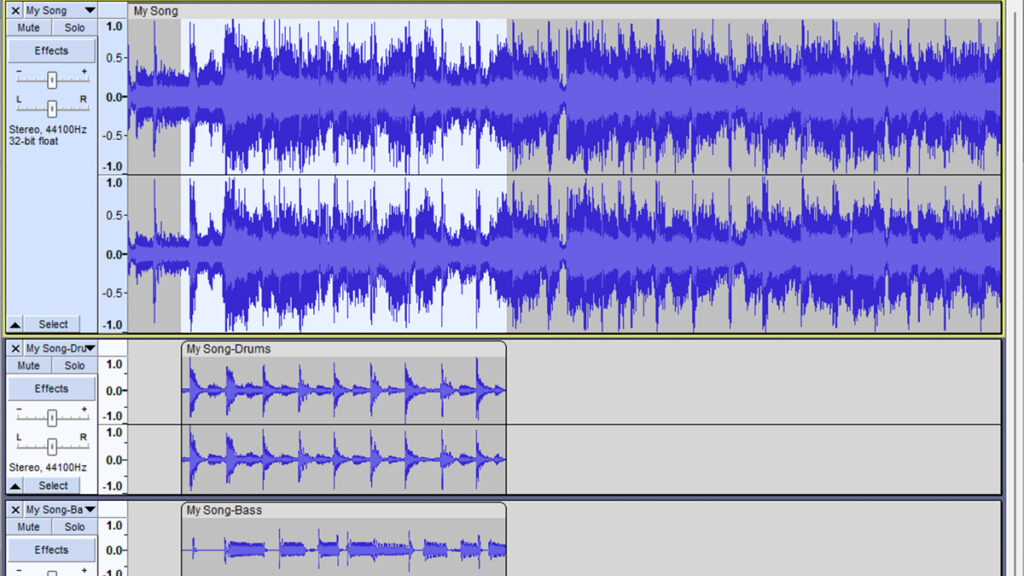
Audacity также научился отделять аудиоконтент из готовых композиций. С помощью плагина Music Separation редактор может отделить вокал от аккомпанемента или разделить всю песню на отдельные дорожки с басом, ударными, голосом и другими инструментами. В качестве дополнения к предыдущему плагину редактор также получил инструмент Stem Separation, разделяющий композиции на стэмы.
Для редактирования записанного сигнала в программу добавили «умные» инструменты Noise Suppression и Whisper Transcription. Первый удаляет любые фоновые шумы из записанного сигнала, второй — транскрибирует шёпот и обычную речь в текст. По мнению разработчиков, оба инструмента особенно пригодятся авторам подкастов.
По словам менеджера по продукту Audacity Мартина Кири, создатели добавили в программу плагины на основе искусственного интеллекта с целью сделать редактор более привлекательным для новых и существующих пользователей. Таким образом разработчики стремятся «предложить возможности, которые ранее были недоступны или попросту труднореализуемы», отметил он.
В разговоре с авторами YouTube-канала Intel Business менеджер также уточнил, что «плагины работают локально на компьютере [пользователя], а не на удалённом сервере, что продиктовано вопросами конфиденциальности». При этом внедрение умных инструментов обработки и генерации звука Кири назвал «всего лишь первым шагом» для команды аудиоредактора, отметив, что в будущем команда создателей планирует расширять библиотеку подобных плагинов.